ConfigCat’s Reliability Framework

When we designed ConfigCat, our main purpose was to create an architecture that is scalable and resilient to short interruptions, so you don't have to worry about latency, service outages, and unwanted glitches in the system.

Cloud-native Infrastructure
Our infrastructure is based on three different cloud providers (Digital Ocean, Microsoft Azure, and Linode) and we run our core services on them. Our traffic manager is in Azure and it uses a performance-based routing method.
Global CDN for Low Response Time
We are building our own CDN service to be agile to customer needs and ConfigCat has globally distributed data centers with multiple CDN nodes to guarantee high availability and low response time.
Our Global CDN provides geo-location-based load balancing on server nodes worldwide to ensure the lowest latency. Currently, we have CDN servers set up in Europe (Amsterdam, Frankfurt), in the USA (Newark, New York City, Fremont, San Francisco), and in the Asia-Pacific region (Sydney, Singapore).

EU CDN to Comply with GDPR
If you would like to stay GDPR-compliant, you can change your Data Governance preferences on the Dashboard and opt to use the EU CDN. By switching to EU CDN, your data will not leave the EU.
ISO 27001 Certified

ConfigCat's ISMS (Information Security Management Systems) has now been certified to ISO/IEC 27001:2013 as of May 31st 2022.
It was determined that ConfigCat's ISMS met the ISO's strict compliance standards for internal security and privacy protection during ConfigCat's certification process. An annual audit cycle will be conducted to demonstrate compliance with ISO standards and demonstrate internal process improvements to maintain this status.
You can download the ISO certificate here and request a copy of the Audit Report by contacting the ConfigCat support team.
Data Privacy & Sticky Percentage Rollouts
When a feature flag value is requested by your application, the SDK evaluates feature flag values locally on the client-side and returns them, ensuring that no user data leaves the client application. To achieve client-side evaluation, we apply the same hashing algorithm on the identifier in all the SDKs and give the User Object a specific number on a scale of 0-100.
For instance, a particular user object gets 12 as the hashed number and you set 10% - On in the Dashboard. The targeted user won’t get the feature because 12 is bigger than 10. If you raise the amount to 20%, the user will get the feature because 12 is less than 20. This way we guarantee the stickiness of our percentage rollouts, meaning that if in the above example you decrease the percentage to 10%, again the user will not get the feature. Since all of our SDKs are open source, you can check how this mechanism works.
This is how percentage evaluation looks like in our CommonJS SDK:
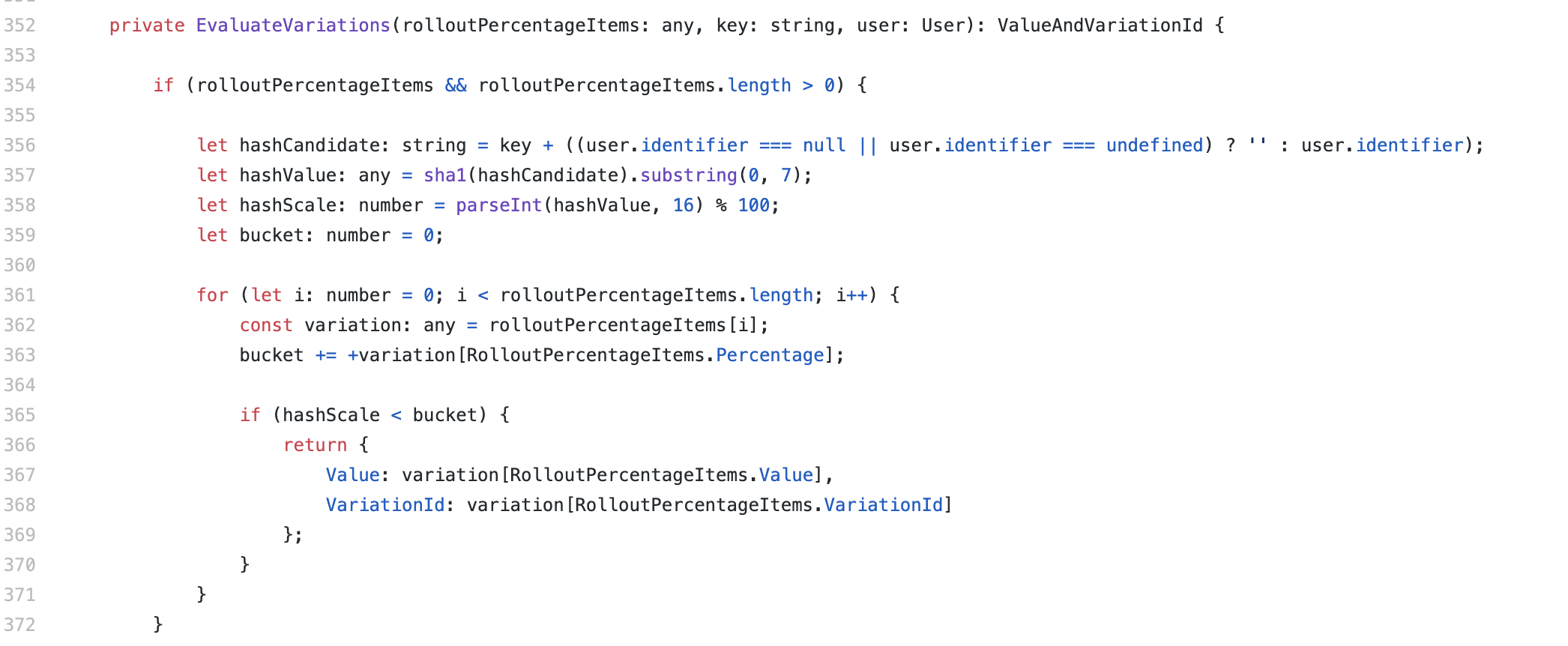
Based on the percentage set in the ConfigCat Dashboard, we evaluate the feature on the client-side with the help of this specific number. This way, you can control what type of data (name, key, description, value, targeting rules, and percentage rules) will travel between your apps and ConfigCat CDN servers.
Comparator for Sensitive Data
Let’s suppose that for your frontend application, you would like to target users based on sensitive data (e.g., email addresses, names, etc.). In such cases, you can add a layer of protection to that information using a sensitive text comparator. When selecting a condition on the Dashboard, you can choose the IS ONE OF or IS NOT ONE OF sensitive comparators when targeting users to convert the information into a unique hash value.

Unit Tests for Consistent User Experience
As the evaluation happens on the client-side, we’ve created over 1,200 SDK unit tests to ensure that all our SDKs are consistent in delivering the same feature flag value to the same users in different clients. As long as you pass the same unique identifier in all the SDKs, the targeted user gets the exact same experience every single time, regardless of the platform used.
SDK Local Cache & Fallback Value
If your application can't connect to ConfigCat (e.g., due to internet connection issues), you can continue working with the locally cached value without interruption. This means that ConfigCat SDKs are caching the configurations, so if our CDN server is unreachable, the SDKs will work from the cached configuration. Suppose an SDK couldn't download and cache the configuration at least once. In that case, the getValue calls will return to a fallback value parameter (defaultValue), which is a required parameter in getValue calls. When ConfigCat's CDN is available again, the cached value will get refreshed based on the selected polling mode.

Another important aspect of our SDKs is that we cache all the configuration data in them, resulting in high-speed client-side evaluation. Almost all of ConfigCat SDKs use a default in-memory cache implementation. For instance, the JavaScript-based SDKs use an in-memory plus a local storage cache. The mobile SDKs use a default in-memory cache implementation, but you can set up your custom caching for both iOS and Android so that they can live longer than your app's lifetime.
We are open to any type of feedback or feature request. Join our Community Slack and share your thoughts with us about ConfigCat.